
I’ve come to view the Continuous Thought Machine (CTM) as one of the most compelling directions in deep learning right now. Its real beauty isn't just in the performance, but in how it challenges our assumptions about model structure—giving a network the agency to discover its own internal rhythm through inductive biases inspired by the human brain.
The standout feature for me is the latent space. Instead of relying on traditional fixed layers, the CTM uses a synchrony matrix to encode temporal relations between neurons. This serves as the primary engine for attention and output. It hints at a future where we don't scale computation by just piling on more tokens, but by allowing for richer, deeper internal dynamics over time.
Before we dive into the weeds, I highly recommend playing around with the official interactive page to get a feel for how these dynamics actually move:
Why We Need to Decouple Scaling from Data
Transformers are undeniably powerful, and post-training tricks like RLVR have done wonders for "unlocking" reasoning. But there’s a catch: that reasoning is almost always tethered to the length of a Chain-of-Thought (CoT) sequence.
This creates a frustrating bottleneck: our scaling is stuck to our data.
- Transformers are notoriously data-hungry.
- CoT often feels like an architectural "hack"—sometimes the value isn't the words themselves, but simply the extra time given to the residual stream to process information .
- Linking "thinking" to "token generation" feels biologically "off." Humans do a massive amount of complex reasoning without uttering a single word, though the extent of that is still a hot topic in cognitive science .
The CTM flips the script. Its synchrony matrix scales independently of the data volume. This is a massive shift, but it leaves us with a new puzzle: how should these internal temporal dynamics actually talk to the external data coming in?
My Investigations: Motivations and Interventions
I started digging into the CTM after noticing two specific behaviors in the original paper:
- The "Quick Finish": The model often hits a ceiling early (around on CIFAR-10).
- Sensory Overload: It forces fresh input () into the system at every single tick.
In the real world, we don't just stare at a problem until we solve it; we look, we internalize, and then we "dwell" on the thought while ignoring distractions. I wanted to see if I could nudge the CTM to learn that same rhythm: early exploration (seeking data) followed by internal consolidation (trusting its own thoughts).
I tested two main interventions.
1. The Perceptual Gate (PG)
To give the model a "filter," I added a Perceptual Gate (PG). This produces a scalar retention score based on the model's own action synchrony. It essentially decides the mix between what the model is currently thinking () and what it's seeing ():
- When : The model "closes its eyes" and focuses on internal refinement.
- When : It prioritizes the fresh sensory data.
This setup makes the model’s behavior incredibly easy to interpret—you can literally see when it decides it’s seen enough.
2. The Exploit & Explore Loss
I also tweaked the loss function to reward this "look then think" behavior. Along with the standard CTM ticks, I defined two specific moments:
- (The "Aha!" moment): Peak novelty in attention.
- (The "Thinking" moment): Peak change in the internal activations.
I then added a regularization term:
This is a gentle nudge that says: "Don't ignore the world when you're supposed to be looking, and don't let the world distract you when you're supposed to be thinking."
What the Data Shows
I ran the full "both" configuration (PG + Loss) against a standard baseline on CIFAR-10 for 200k iterations.
Stability and Overfitting
The "both" condition didn't just perform better; it was significantly more stable. It carved out a much smoother Pareto-dominant accuracy curve.
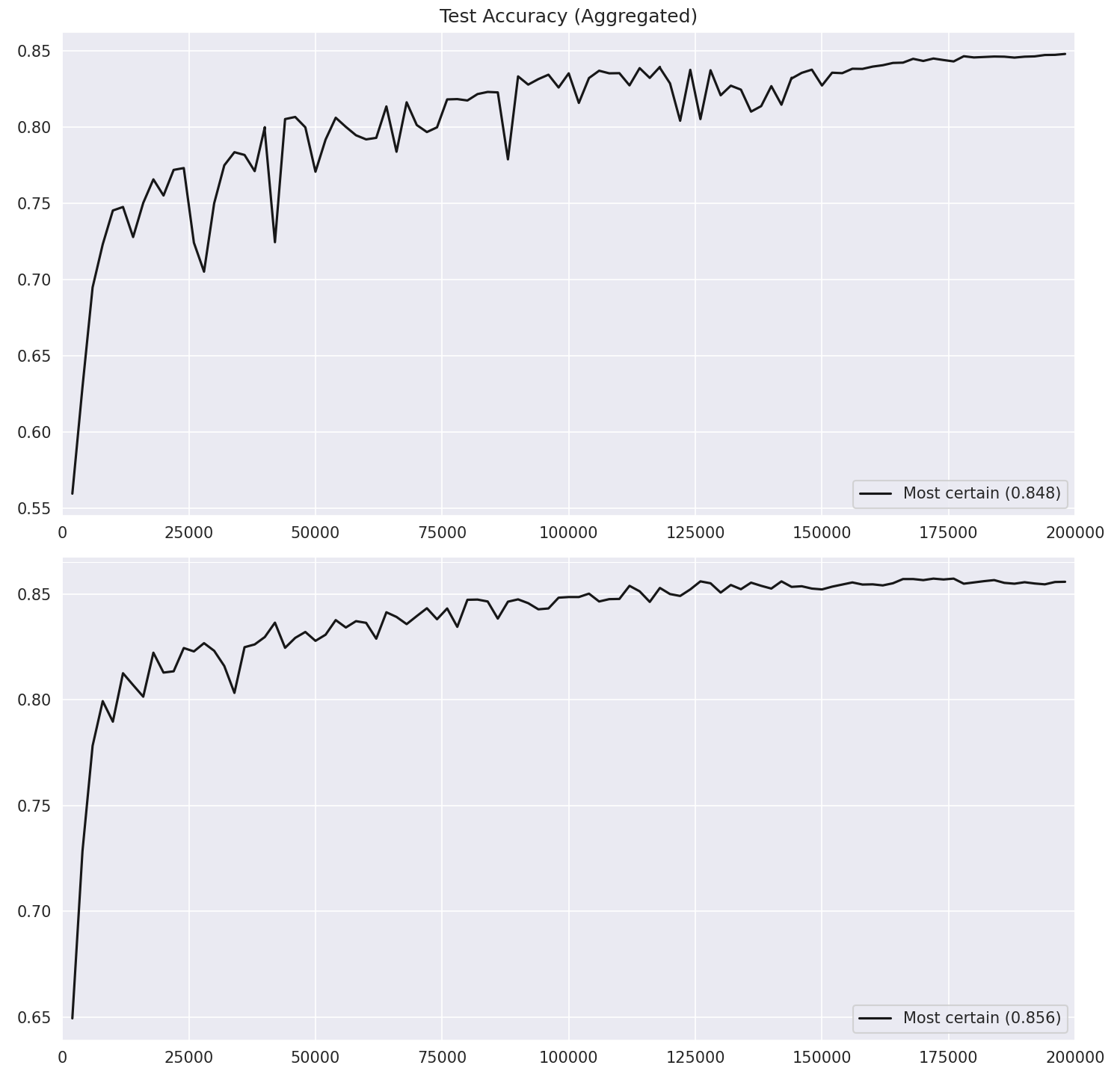 Figure 1: Test accuracy. Notice how the "both" condition (bottom) is much less jittery and hits higher peaks. That said, there’s no free lunch. The "both" condition overfits like crazy. By giving the model more capacity and more specific supervision per sample, it becomes very good at memorizing the quirks of the training set.
Figure 1: Test accuracy. Notice how the "both" condition (bottom) is much less jittery and hits higher peaks. That said, there’s no free lunch. The "both" condition overfits like crazy. By giving the model more capacity and more specific supervision per sample, it becomes very good at memorizing the quirks of the training set.
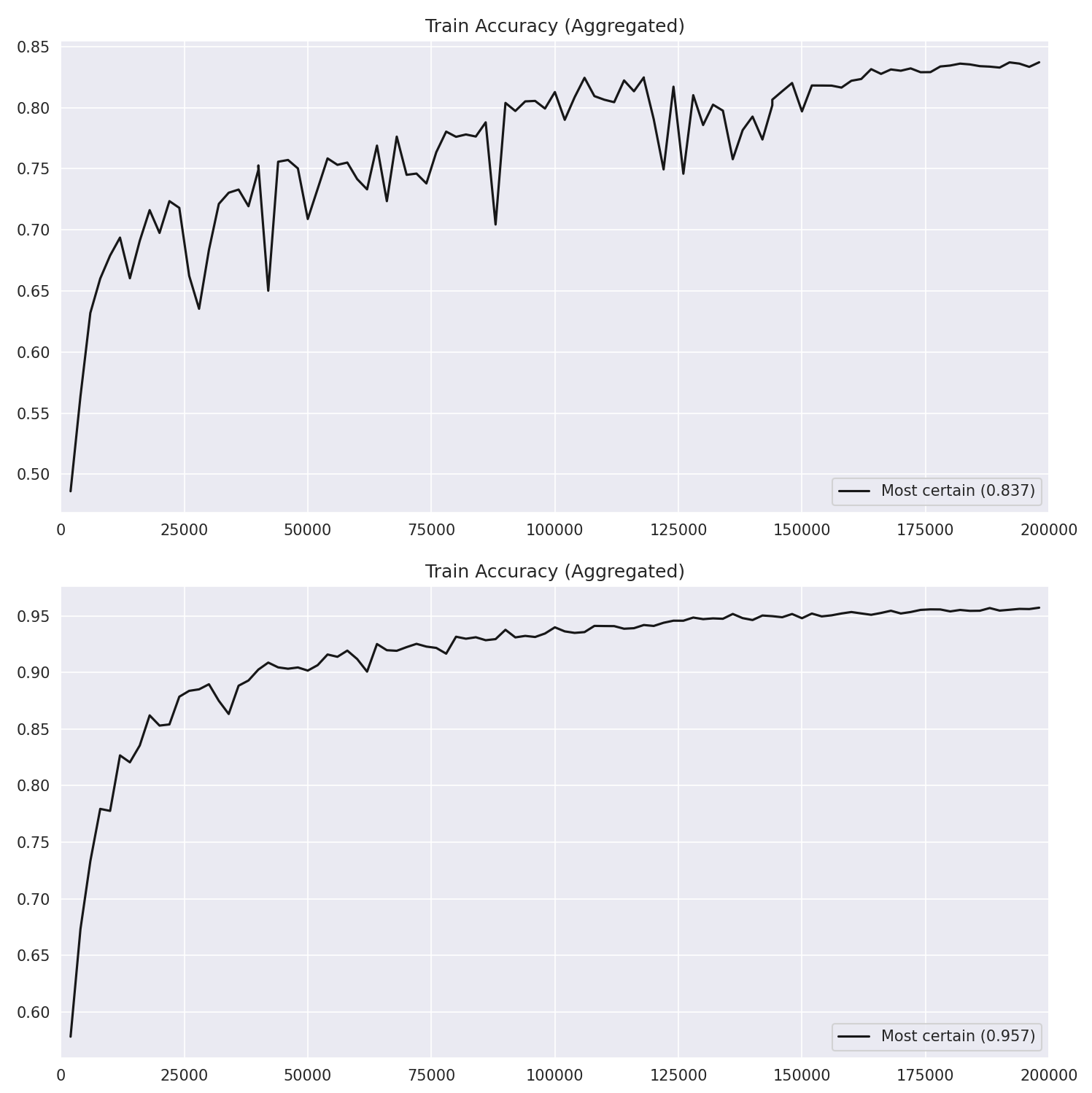 Figure 2: The flip side—significant overfitting when we combine the gate and the loss. ### When Does the Model Decide?
Figure 2: The flip side—significant overfitting when we combine the gate and the loss. ### When Does the Model Decide?
In the baseline CTM, the model usually makes up its mind almost immediately (around tick 12).
With my changes, that "rush to judgment" disappears. The model starts spreading its decisions across the mid-range ticks (averaging around 22). It’s as if the model finds a likely candidate quickly, but then uses the extra time to double-check its work.
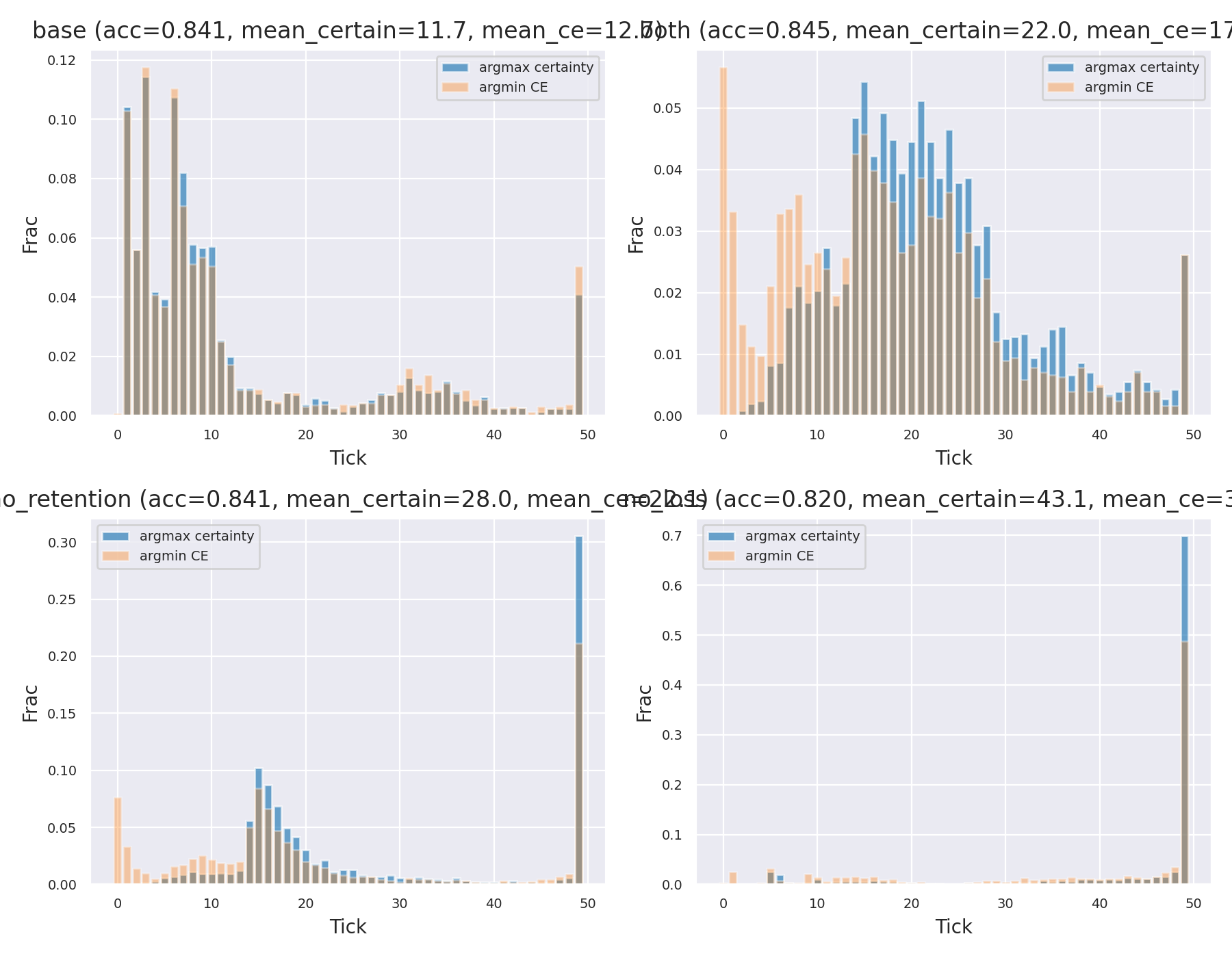 Figure 3: Distribution of certainty. The baseline (blue) is impatient; the "both" version takes its time. ### Per-Tick Performance
Figure 3: Distribution of certainty. The baseline (blue) is impatient; the "both" version takes its time. ### Per-Tick Performance
This is where it gets interesting. The baseline CTM actually gets worse if you let it think too long (past tick 10). But the "both" condition stays rock-solid at about 83-84% accuracy across the whole timeline.
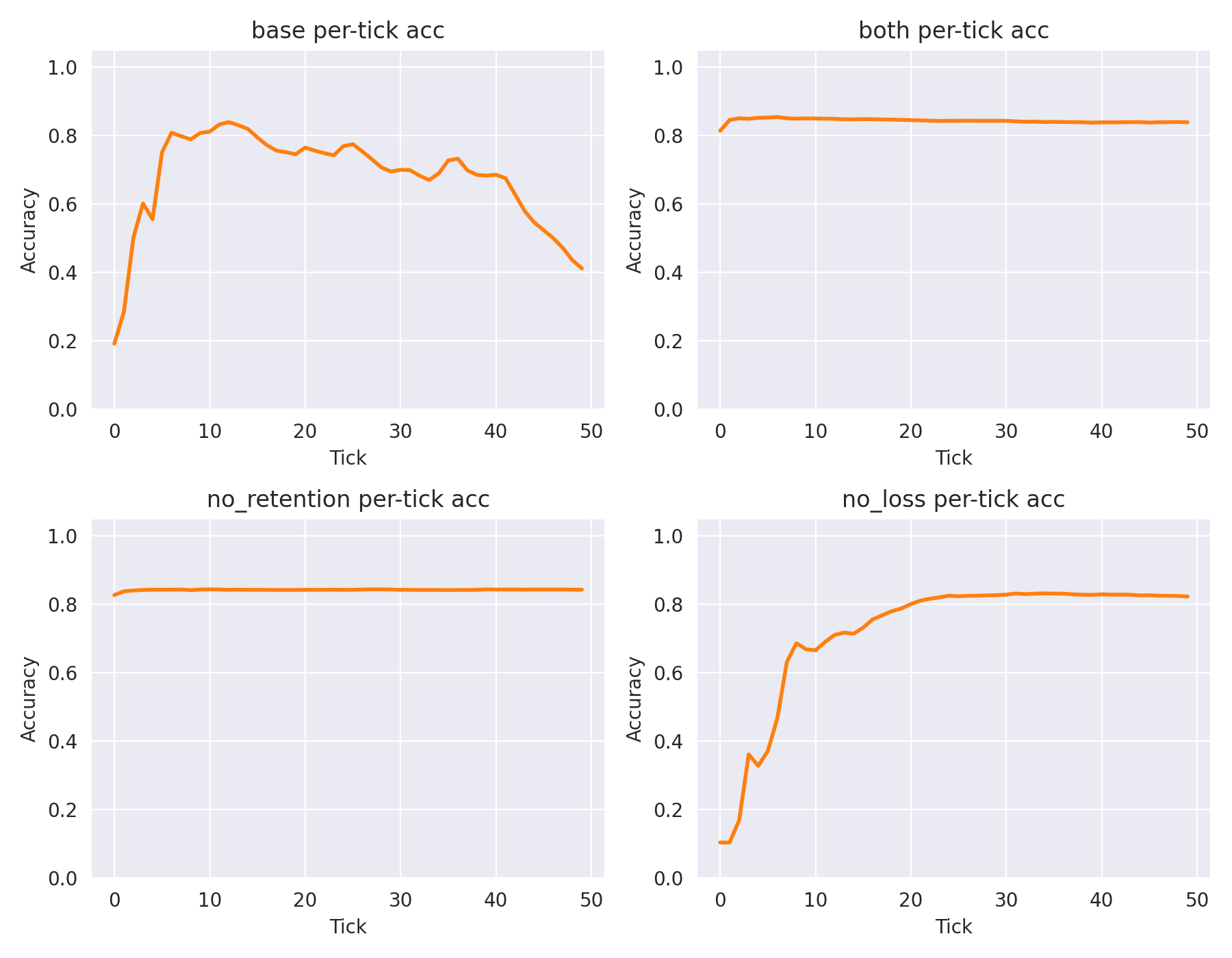 Figure 4: Baseline accuracy falls off a cliff over time, while our version stays flat. This tells us the model isn't necessarily finding new info in those later ticks—it's just organizing its existing beliefs better.
Figure 4: Baseline accuracy falls off a cliff over time, while our version stays flat. This tells us the model isn't necessarily finding new info in those later ticks—it's just organizing its existing beliefs better.
Early Exit: The Best of Both Worlds
Because the accuracy is so high even in the early stages, these models are perfect for "early-exit" strategies. If you tell the model to stop as soon as it's 80% sure, the "both" version hits that target much faster and with way better accuracy than the baseline.
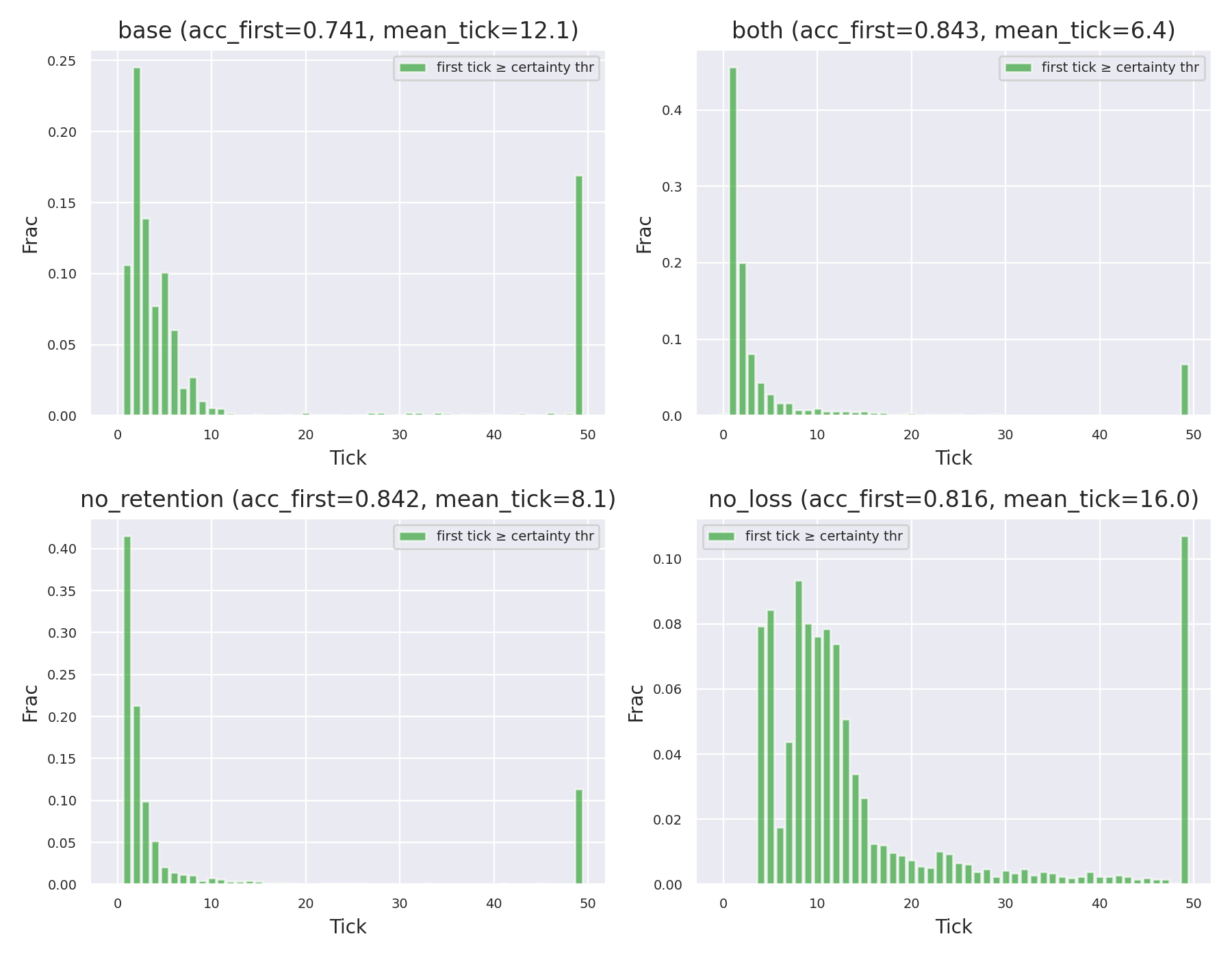 Figure 5: Reaching the 0.8 certainty threshold happens faster and more accurately in the modified model. ### The S-Curve of Thought
Figure 5: Reaching the 0.8 certainty threshold happens faster and more accurately in the modified model. ### The S-Curve of Thought
Finally, I checked the retention score to see if the model actually learned the "look then dwell" strategy. It did. The curve is a near-perfect S-shape: low retention (looking) at the start, rising to near 1.0 (internal dwelling) by the end.
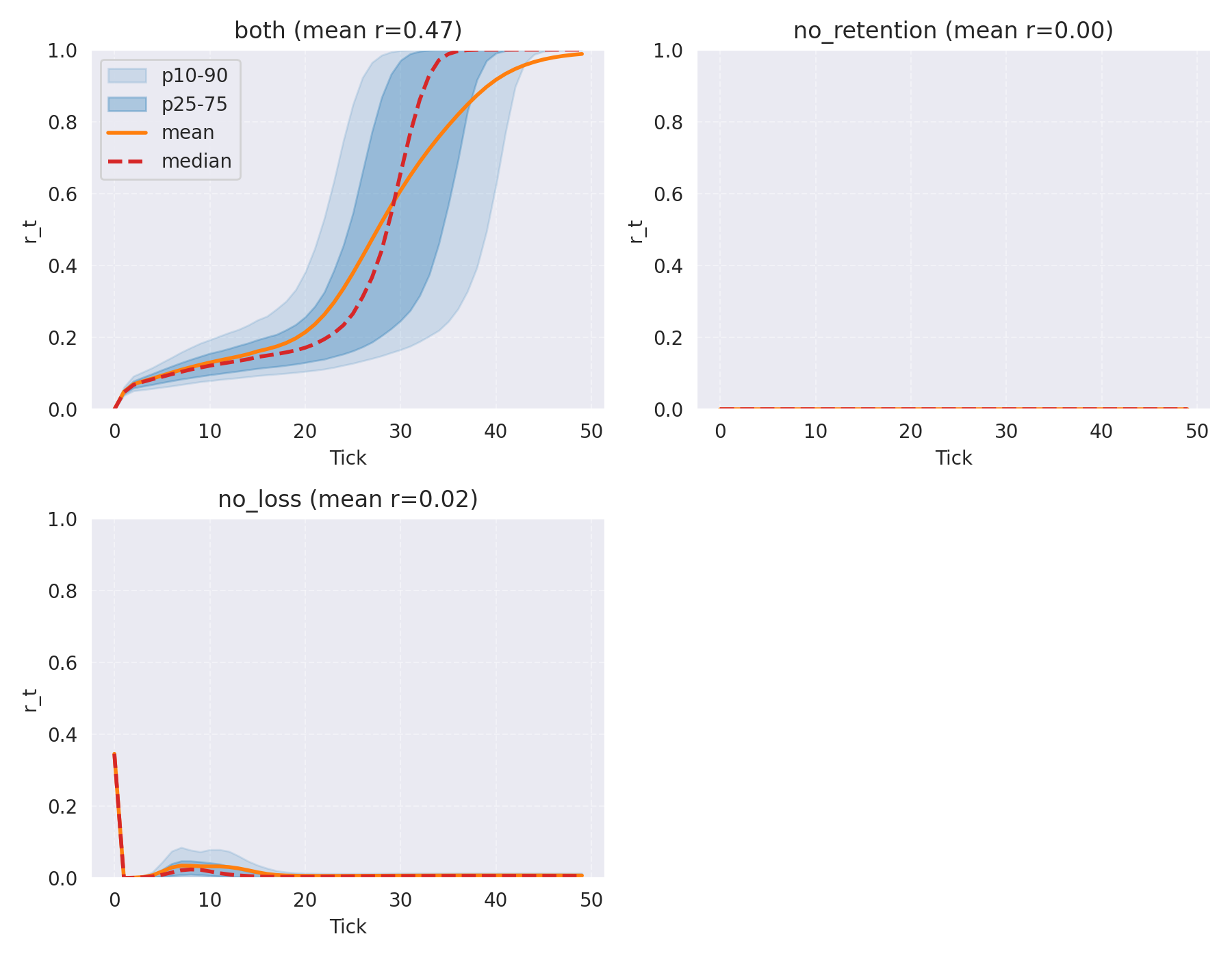 Figure 6: The "both" condition (left) shows a clear, logical progression from external perception to internal thought. ## Closing Thoughts
Figure 6: The "both" condition (left) shows a clear, logical progression from external perception to internal thought. ## Closing Thoughts
The CTM is remarkably sensitive to how we structure its "thinking time." By introducing the Perceptual Gate and a more nuanced loss function, we moved the model away from "lazy" strategies toward a much more structured form of computation.
We aren't just chasing a higher accuracy percentage on CIFAR-10 here. The real goal is proving that we can deliberately shape how a model allocates its internal resources. As we move toward more complex tasks, being able to tune "thinking time" will be just as important as tuning the weights themselves.